
 红包分享
红包分享 钱包管理
钱包管理

 0
0- 0
- 0
- 0
2023年作为AI大模型的发展“元年”,见证了人工智能技术在全球范围内的跨越式发展。这一年,AI浪潮以前所未有的势头进行着革命性的突破,重塑了产业格局。在这场技术变革中,小米凭借独特的技术洞察,开创性地提出了将"轻量化、本地部署"作为突破点,业界第一个在手机芯片NPU上跑通十亿参数规模大语言模型,验证了端侧小模型在部分目标场景可以取得媲美云端大模型的效果。
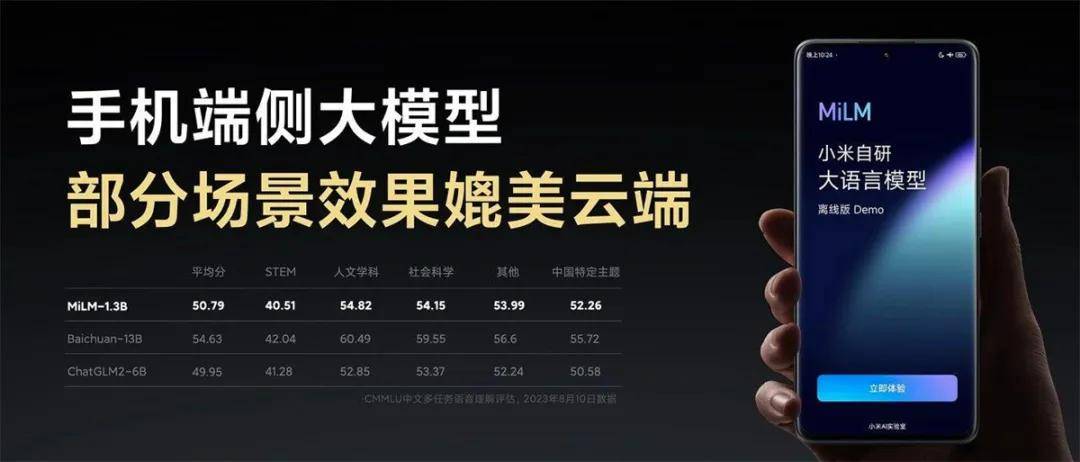
【2023年8月小米首次发布小米自研大模型并跑通端侧】
而过去的这一年多时间里,国内自主研发的大模型生态系统日趋完善,在激烈的市场竞争中,技术迭代周期不断压缩,大模型的产业落地进程明显加速,与此同时,多模态技术与智能体等前沿领域正在开启技术创新的新篇章,成为引领行业发展的新动能。
在模型规模方面,我们见证了一个极具特色的发展趋势:
• 向下突破:面向端侧部署的轻量级模型蓬勃发展(如Phi-mini-3.8B、Gemma-2B等),为边缘计算提供了更多可能
• 向上拓展:大规模云端模型持续进化(如Llama3.1-405B、Mistral-105B等),以满足高性能计算需求
这种"双向突破"的技术路线,不仅展现了AI技术的极致追求,更彰显了其在实际应用中的灵活适配能力。
在此行业背景下,小米大模型团队亦专注于提升自研大模型的模型能力和「端」「云」协同的落地效果,力求以行业领先的AI能力全面赋能「人车家全生态」战略,实现多个场景下的无缝衔接,为用户提供全方位的智能服务,打造更加智慧和便捷的生活体验。而小米第二代自研大模型的推出无疑是这一战略的重要支撑点。

目前小米大模型已经实现了从一代到二代(MiLM2)的升级迭代。此次迭代不仅扩充了训练数据的规模、提升了数据的品质,更在训练策略与微调机制上进行了深入打磨,增强了技术实力并全面升级了配套的部署技术。小米第二代大语言模型的几个主要升级是:
• 第二代大语言模型丰富了模型的参数矩阵,参数规模同时向下和向上扩充,实现了云边端结合,参数尺寸最小为0.3B,最大为30B;
• 第二代大语言模型在10大能力维度上,相比于第一代模型平均提升超过45%,其中指令跟随、翻译、闲聊等对于智能助手而言比较关键的能力上,效果处于业界前列;
• 第二代大语言模型在端侧部署上支持3种推理加速方案,包括大小模型投机、BiTA、Medusa,并且自研量化方案相比于业界标准高通方案,量化损失降低78%;
• 第二代大语言模型支持的最长窗口为200k(第一代为4k),在长文本评测中,效果处于业界前列。
01 小米自研大模型技术探索与创新
小米大模型团队在预训练、后训练、量化、推理加速等方向做了大量的技术探索和创新,并将部分成果以论文的形式发布出来,推动大模型技术的发展。
在2024年,小米大模型团队发表了11篇论文(5篇ACL、3篇EMNLP、1篇NeurIPS、1篇ECAI、1篇COLING),申请了30+项发明专利,其中部分代表性的工作如下:
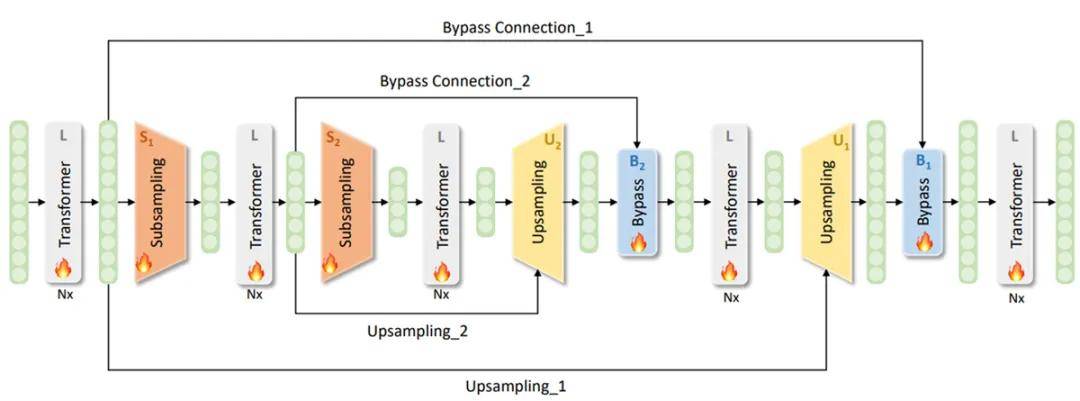
• SUBLLM:基于transformer结构,创新性地提出了一种新的模型结构,设计了Subsampling、Upsampling和Bypass等新模块,使得模型能够区分重要token和不重要token,针对重要tokens花更多的算力学习,保持few shot能力不变的同时,训练和推理速度分别提升34%和52%,对标Google Deepmind的mixture of depths工作,兼容现有attention based大模型生态。
• TransAct 大模型结构化剪枝方法:为了在大模型上同时实现高度压缩和较小损失,小米大模型团队设计了 TransAct 剪枝方法。本方法以减小 Transformer 模块内隐藏表征维度为目标,以各神经元的激活值大小为依据,剪除激活值较小的神经元,形成类低秩表示的模块结构,同时保留 LayerNorm 等对扰动敏感的模块间隐藏表征维度。对比之前业界最佳的剪枝方法,TransAct方法剪枝模型的KV Cache下降了50%,推理速度提升了20%(小米14手机测试)。

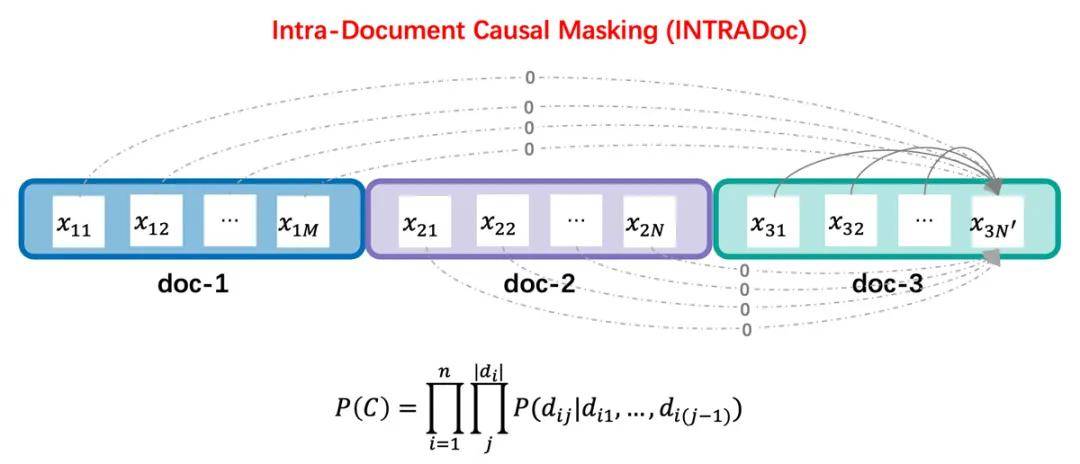
• INTRADoc注意力机制:通过屏蔽无关文档,让每个token的概率仅取决于同一文档中的上文信息,进而消除了来自之前无关文档的潜在干扰信息,并显著地提高了模型上下文学习、知识记忆、上下文利用能力。
• Mixture of Diverse Size Experts :一种新的MoE结构,名字叫MoDSE,在每一层中设计大小不同的专家结构,并同时引入了一种专家对分配策略,以在多个 GPU 之间均匀分配工作负载。在多个基准测试中,MoDSE 通过自适应地将参数预算分配给专家,在保持总参数量和专家个数相同的情况下,表现优于传统 MoE 结构。

02 MiLM2实力进阶,二代效果全方位提升
二代模型MiLM2系列融合多项前沿技术,实现技术能力升级的同时模型效果全面超越前代,其中,MiLM2-6B模型与MiLM2-1.3B模型经过进一步升级打磨,实力更上一层楼。
小米大模型团队采用自主构建的通用能力评测集Mi-LLMBM2.0,对最新一代的MiLM2模型进行了全方位评估。该评测集涵盖了广泛的应用场景,包括生成、脑暴、对话、问答、改写、摘要、分类、提取、代码处理以及安全回复等10个大类,共计170个细分测试项。以MiLM2-1.3B模型和MiLM2-6B模型为例,对比去年发布的一代模型,在十大能力上的效果均有大幅提升,平均提升幅度超过45%。
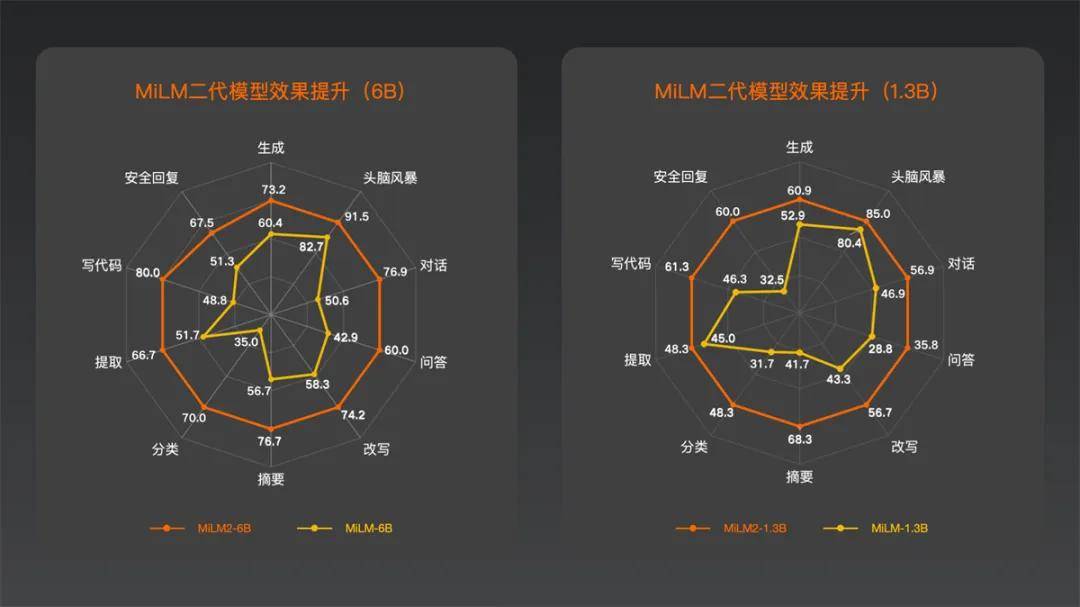
小米的「人车家全生态」战略,旨在构建一个涵盖人、车、家等多元化生活场景的超级智能生态系统。在这个系统内,实时交互成为常态,每时每刻都需要精确对接用户千差万别的个性化需求,这对于大模型的生成、闲聊、翻译等能力提出了更高的要求。在这些关键能力上,MiLM2-6B模型的评测成绩十分优异,对比业内同参数规模模型也有较优的效果。
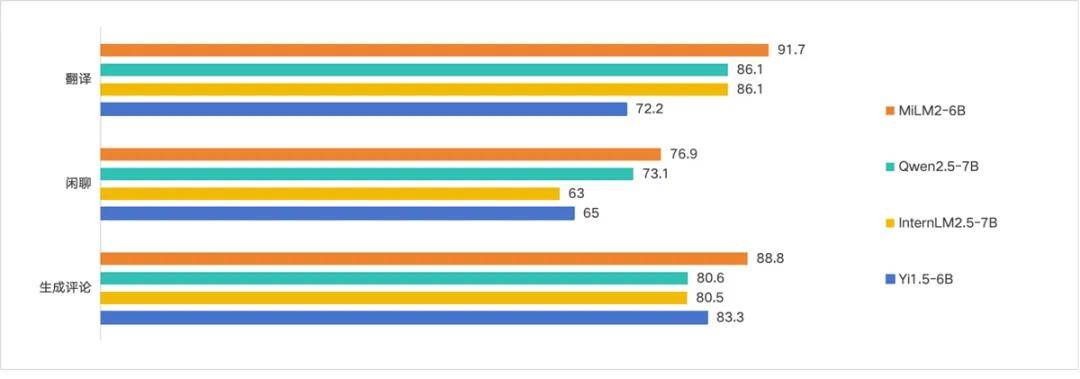
03 MiLM2模型矩阵,云边端结合赋能「人车家全生态」
MiLM2模型矩阵主要在参数规模和模型结构两个方面打造纵深,目的是为了适应多元化的业务场景并在小米生态中挖掘更多的落地场景。

大模型的迭代,也是一个重点突破、打磨模型矩阵的动态过程。在坚持轻量化部署的大原则下,小米自研大模型团队充分考虑了集团内部多元化的业务场景及不同落地场景的资源限制,构建并不断扩充了自研大模型的模型矩阵,将大模型的参数规模灵活扩展至0.3B、0.7B、1.3B、2.4B、4B、6B、13B、30B等多个量级,以适应不同场景下的需求。
• 0.3B~6B:终端(on-device)场景,应用时通常是一项非常具体的、低成本的任务,提供不同参数规模的模型以适配不同芯片及存储空间的终端设备,微调后可以达到百亿参数内开源模型效果。
• 6B、13B:在任务明确、且需要比6B以下参数模型提供更多的零样本zero-shot/上下文学习时,6B和13B是一个可能有LLM涌现能力的起点,支持多任务微调,微调后可以达到几百亿开源模型的效果。
• 30B:云端场景,具备相当坚实的zero-shot/上下文学习或一些泛化能力,模型推理能力较好,能够完成复杂的多任务,基本达到通用大模型水平。
小米自研大模型矩阵不仅包含多样的参数量级,同时也纳入了各种不同的模型结构。在二代模型系列中,大模型团队特别加入了两个MoE(Mixture of Experts,即混合专家模型)结构的模型:
• MiLM2-0.7B×8
• MiLM2-2B×8
两个模型的差异主要体现在训练总参数量、词表大小等方面。MoE模型的工作原理是将多个承担特定功能的“专家”模型进行并行处理,进而综合各模型的输出来提高整体预测的准确度和效率。以MiLM2-2B×8为例,根据评测结果,该模型在整体性能上与MiLM2-6B不相上下、表现出色,而解码速度实现了50%的提升,在保证模型性能不打折扣的同时,提升了其运行效率。
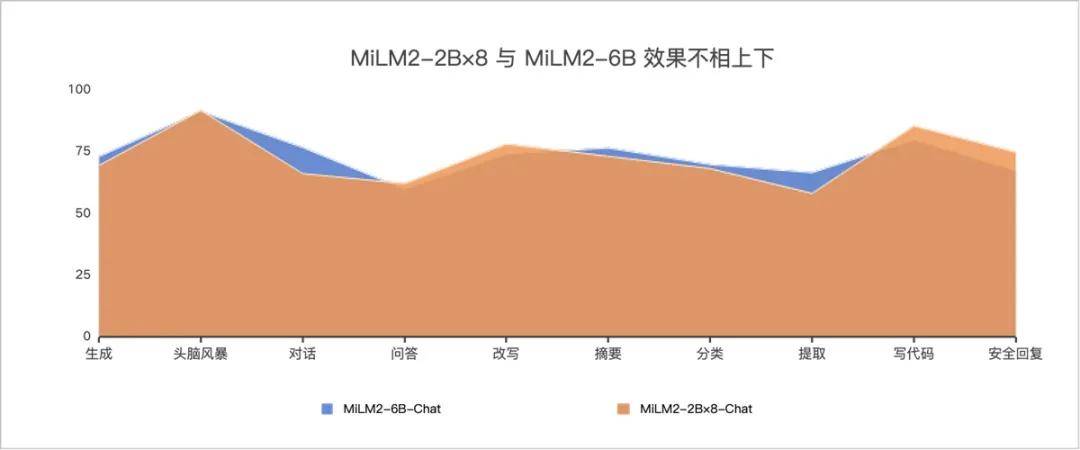
04 「端」「云」并重:4B模型端侧落地,30B模型云端部署
端侧新增4B模型
小米是全球最大的 IoT 设备制造商,不仅需要解决 AI 大模型在终端设备上如何高效部署的问题,攻克存储空间和内存带宽等方面的难题,还需在各类场景中确保用户的隐私和数据安全。去年,小米的大模型团队在端侧部署方面取得了显著进展,使小米成为业界首个在移动设备上成功运行1.3B和6B大模型的公司。随着二代大模型的迭代更新,端侧部署技术也有了新的突破,新的 4B 模型将在端侧发挥更重要的作用。
小米大模型团队创新性地提出了“TransAct 大模型结构化剪枝方法”,仅用8%的训练计算量即从6B模型剪枝了4B模型,训练效率大大提升;同时小米大模型团队自研了“基于权重转移的端侧量化方法”和“基于Outliers分离的端侧量化方法”,大幅降低了端侧量化的精度损失,对比业界标准高通方案,量化损失下降78%。MiLM2-4B模型总共40 层,实际总参数量为3.5B,目前已经实现在端侧部署落地。

• Qwen2.5-3B:Qwen2.5-LLM: Extending the boundary of LLMs (GPQA, BBH, Winogrande, GSM8K, MATH, MBPP-Plus) and OpenCompass (DROP, MULTI-NLI, WorldSense)
• Llama3.2-3B:Evaluate with OpenCompass and Llama-3.2-3B model weight

• Qwen2.5-3B-Instruct结果采用FollowBench和IFEval官方代码测试
云端新增30B模型
MiLM2-30B 模型是小米二代大模型系列中参数量级最大的模型,专为云端场景设计。在云端环境中,大模型面临着多样化和高难度的挑战,需要更高效地遵从并执行用户的复杂指令,深入分析多维度任务,并在长上下文中精准定位信息。针对这些重点目标,大模型团队选择了一系列开源的评测集,对 MiLM2-30B 模型的专项能力进行评估。结果表明,MiLM2-30B 模型在指令遵循、常识推理和阅读理解能力方面均有超越主流竞品的出色表现,具体的评测集和评测结果如下:
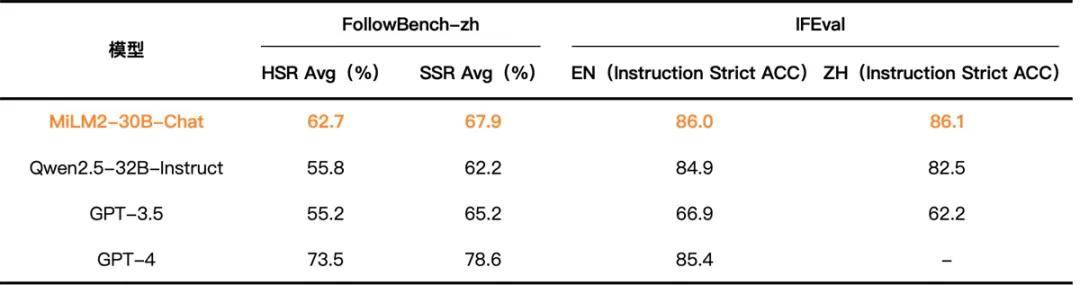
• GPT-3.5和GPT-4:FollowBench,IFEval (Zhou et al., 2023)
• Qwen2.5-32B-Instruct结果采用FollowBench和IFEval官方代码测试

• Llama3.1-70B:The Llama3 Herd of Models
• Qwen2.5-32B:Qwen2.5-LLM: Extending the boundary of LLMs (GSM8K, MATH, winogrande) and OpenCompass (Drop)
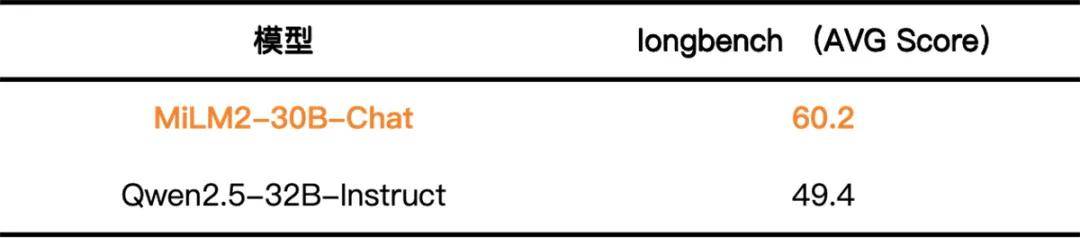

• Qwen2.5-32B-Instruct结果采用github.com/THUDM/LongBench代码测试得到,包含所有中文和代码测试集
目前,小米第二代自研大模型取得的进步和成果,已经开始渗透到真实的业务场景与用户需求中,不仅帮助集团内部解决了多样化的业务需求、实现工作提效,也已经在澎湃OS、小爱同学、智能座舱、智能客服中开始应用落地。

未来,小米大模型团队将持续探索前沿技术,不断突破自我,以期在云边端结合的框架下,实现自研大模型的全面升级与应用,为用户提供更加智能、便捷、个性化的服务。同时,团队还将紧密围绕「人车家全生态」场景,深入挖掘用户需求,不断优化产品功能,致力于打造一个更加智能、安全、舒适的生活环境,让科技更好地服务于人类生活。

